Introduction
When a Burmese-speaking developer asks their AI assistant “Python ဖြင့် list ကို sort လုပ်နည်း” (How do I sort a list in Python?), the response should not just be code — it should include a clear explanation in Myanmar language.
Burmese-Coder-4B was built to make this possible.
Architecture & Training
Base Model
Burmese-Coder-4B is adapted from the Gemma-3 4B family. The goal is not only “correct code”, but also stable Burmese explanations without mixed-script contamination.
Two-Stage Adaptation: SFT → DPO
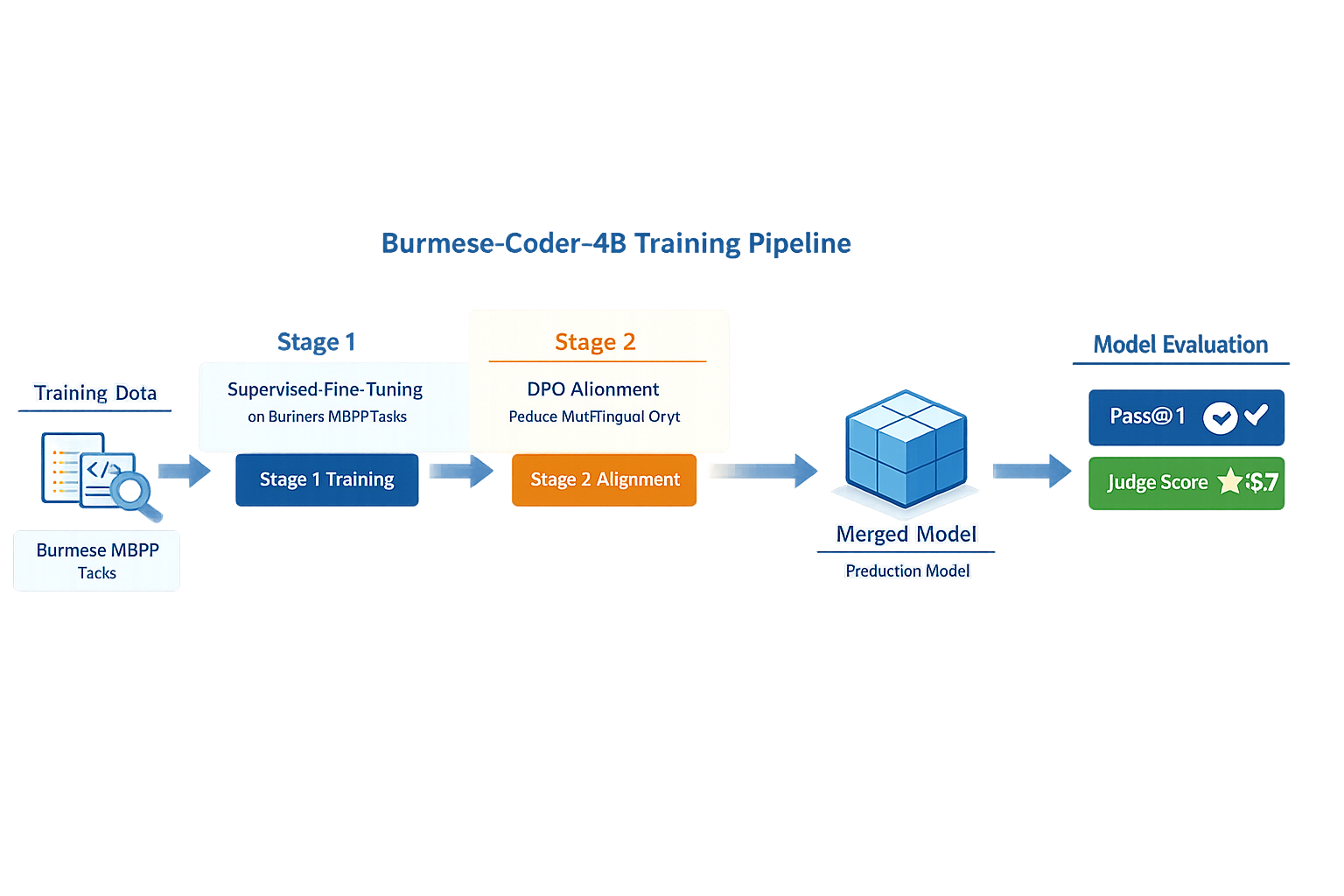
The technical whitepaper describes a two-stage pipeline:
Stage 1 — Supervised Fine-Tuning (SFT) using LoRA (4-bit loading):
- Context length: 2048
- LoRA rank: 16
- LoRA alpha: 16
- Batch size: 16
- Gradient accumulation: 4
- Learning rate:
2e-4 - Warmup steps: 15
Stage 2 — Direct Preference Optimization (DPO) alignment (to reduce multilingual drift):
- Context length: 2048
- 4-bit loading
- Batch size: 2
- Gradient accumulation: 16
- Learning rate:
3e-6 - Max steps: 300
- β: 0.5
Training Data (Authoritative)
Per the whitepaper, the supervised training corpus is Burmese MBPP (974 tasks). Each instance includes:
- a Burmese instruction
- a Python solution
- a Burmese explanation of the code logic
For held-out functional evaluation, the benchmark is Burmese HumanEval (run via the burmese-coding-eval pipeline).
Evaluation: burmese-coding-eval (Two-Track)
The whitepaper uses a two-track evaluation framework:
Metrics
| Track | Metric | Description |
|---|---|---|
| Functional | Pass@1 | Unit-test correctness on Burmese HumanEval |
| Judge-based | Rubric score | LLM-as-a-judge scoring across multiple dimensions |
The judge-based rubric evaluates: fluency, instruction following, semantic correctness, terminology quality, and a mixed-language penalty. Rubric scores are reported with two separate judges: Gemini 2.5 and DeepSeek V3.
Main Results (from the whitepaper)
| Model | Pass@1 (%) | Rubric (DeepSeek) | Rubric (Gemini) |
|---|---|---|---|
burmese-coder-4b | 62.0 | 3.456 | 3.779 |
gemma3_4b | 62.0 | 2.939 | 3.203 |
qwen2.5_3b | 45.0 | 1.220 | 2.526 |
Mixed-language contamination drops sharply after alignment:
- Under Gemini: 0.69 → 0.02
- Under DeepSeek: 0.72 → 0.09
Where to Get It
For the main project links and the latest release artifacts, use the project pages:
Impact
Burmese-Coder-4B represents the first serious attempt to bridge the gap between:
- Modern code generation AI (GitHub Copilot, Claude, GPT-4)
- Myanmar-language developers who think, document, and communicate in Burmese
By making LLMs accessible in Myanmar language, we lower the barrier for thousands of developers who would otherwise have to navigate AI assistance exclusively in English.
Try It
References & Related Links
- Burmese-Coder-4B Core Project Page
- burmese-coding-eval Framework
- Burmese GPT Base Architecture
- HackerNoon Feature: Read the Feature Article
Keywords: Burmese-Coder-4B, Myanmar LLM, Gemma fine-tuning, QLoRA, Burmese code generation, Myanmar developer tools, WYNN747, Dr. Wai Yan Nyein Naing